
芯动力RPP架构成功适配微软BitNet,打造端侧AI高效推理新生态
BitNet为边缘AI的加速普及带来新活力。
微软开源BitNet模型结合芯动力RPP生态架构,可在边缘和端侧智能设备上快速适配和部署新的模型,为边缘AI的加速普及带来新的活力。
【内容目录】
1.什么是BitNet?
2.BitNet的优势何在?
3.国外企业在BitNet与硬件适配方面的具体实践
4.国内厂商基于BitNet架构的“端侧AI”模型轻量化尝试
5.BitNet模型与新兴具身机器人应用
6.BitNet有望引爆家电、汽车和手机市场
7.结语
01.
什么是BitNet?
最近微软发布了首个开源的“原生1bit”LLM -- BitNet b1.58 2B4T,参数规模达到20亿,训练数据高达4万亿token,从根本上重构了AI的计算引擎。它用超高效的加法运算,取代了AI模型中最昂贵的浮点乘法运算。
传统LLM(如GPT系列)依赖于高精度的16位或32位浮点数,或低精度的8位及4位整数,来表示模型中的“权重”,而BitNet则采取了一种更为激进的三元表达方法。BitNet模型中的每一个权重都只能是如下三个值之一:-1、0 或 +1,即在训练的时候就是训练为-1,0,1,所以在推理的时候没有精度损失。
这种设计被称为三元量化(Ternary Quantization),因为它使用了大约1.58个比特(log 2(3)≈1.58)的信息来存储每个权重,最终效果并不比高精度方法差。
实现这一目标的核心是其创新的BitLinear层。在标准的Transformer模型(现今大多数LLM的基础架构)中,矩阵乘法是计算的核心和瓶颈。BitLinear层用更高效的加法和减法取代了这些昂贵的乘法运算,因为对-1、0、1的操作本质上就是加减法。
重要的是,BitNet模型是从零开始就使用这种三进制方式进行训练的,即量化感知训练(Quantization-Aware Training, QAT),这使得模型能够在低比特的限制下依然保持高性能,而非简单地对已训练好的模型进行压缩。
02.
BitNet的优势何在?
BitNet的革命性并非空谈,其优势直指当前AI发展面临的核心痛点:巨大的计算资源消耗和高昂的成本。其优势表现在:
1. 极致的效率和成本效益:
▪ 内存占用大幅降低:由于每个权重仅需约1.58位,相比于16位浮点数,BitNet可以将模型的内存占用降低约10倍。这意味着,过去需要庞大数据中心才能运行的大型模型,未来也许可以直接在个人电脑甚至智能手机上流畅运行。
▪ 计算速度显著提升:用加减法替代乘法,极大地简化了计算过程。这不仅意味着更快的推理速度,也使得通过边缘设备的CPU+NPU计算组合高效运行LLM成为可能,摆脱了对昂贵且稀缺的GPU芯片的依赖。
▪ 能耗大幅下降:更简单的计算和更小的模型尺寸直接带来了能耗的显著降低。这使得在笔记本电脑、智能汽车、物联网设备等对功耗敏感的边缘设备上部署强大AI成为现实,同时也响应了全球对绿色计算和可持续发展的呼吁。
下面的图表是BitNet与Llama大模型在存储要求和解码性能方面的对比。
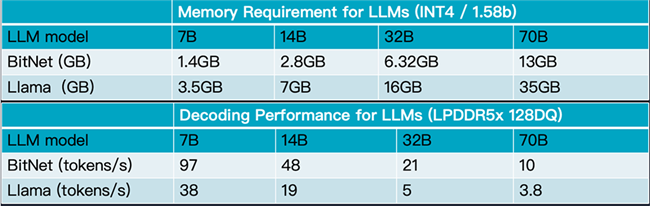
2. 保持高性能:令人惊讶的是,这种极致的压缩并没有以牺牲性能为代价。微软的研究表明,在一定模型规模(例如30亿参数)以上,BitNet b1.58模型的性能(如困惑度和下游任务表现)可以媲美甚至超过同等规模的半精度(FP16)模型,这打破了“模型越大且精度越高,性能才越强”的传统认知。
下图是BitNet与目前主流模型的参数性能对比。

可以看出,BitNet并非要完全取代Transformer架构,而是对其核心计算方式的一次“魔改”。它保留了Transformer强大的结构和能力,但通过釜底抽薪的方式解决了其效率和成本问题。
03.
国外企业在BitNet与硬件适配
方面的具体实践
尽管微软的BitNet技术在AI社区引起了不小的反响,但截至目前,国外大型电子硬件公司(如苹果、三星、高通等)尚未公开发布任何已将BitNet直接集成到其产品中的具体实践或合作项目。
然而,这并不意味着适配工作没有在进行中。由于BitNet技术还非常新,相关的实践目前更多地体现在社区驱动的实验、性能基准测试以及为未来适配铺路的软件框架上。以下是当前国外企业和开发者社区在BitNet与智能硬件适配方面的主要动态:

1. 核心推动力:bitnet.cpp框架
微软官方开源的bitnet.cpp是推动BitNet走向智能硬件的关键。它是一个专门为1-bit LLM设计、高度优化的推理框架。
▪ 专为CPU设计:bitnet.cpp的核心优势在于它可以在没有昂贵GPU的情况下,高效地在CPU上运行。这直接契合了绝大多数电子产品(如智能手机、笔记本电脑、物联网设备)的硬件配置。
▪ 跨平台支持:该框架支持在主流的x86架构(如英特尔、AMD处理器)和Arm架构上运行。Arm架构是几乎所有智能手机和众多平板电脑、边缘设备的核心,因此bitnet.cpp的Arm优化是其在智能终端领域应用的基础。
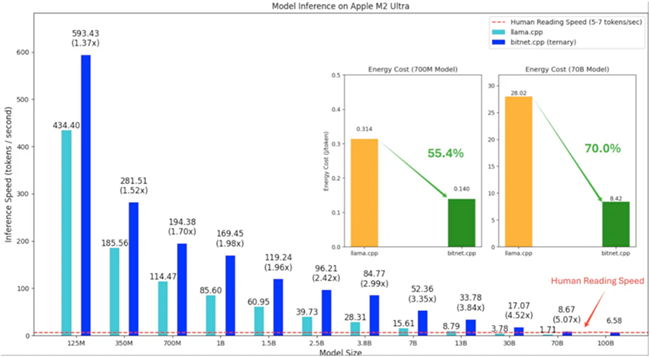
2. 在Arm硬件上的性能表现
根据微软官方测试数据,已有的基准测试展示了BitNet在常用硬件上的巨大潜力:
▪ 显著的速度提升:在ARM CPU(如苹果的M系列芯片)上,使用bitnet.cpp运行BitNet模型,相比于传统的16位浮点模型(fp16),速度有1.37倍到5.07倍的提升,且模型越大,加速效果越明显。
▪ 惊人的能效:在能耗方面,bitnet.cpp在Arm CPU上的表现同样出色,能够将能耗降低55%到70%。这对于依赖电池供电的移动设备来说是至关重要的优势。
▪ 实现“不可能的任务”:测试表明,bitnet.cpp甚至可以在单个CPU上运行高达1000亿参数的BitNet模型,其速度足以达到人类的正常阅读水平(约每秒5-7个词元)。这在过去是无法想象的,它意味着未来极其强大的AI模型或许可以直接在用户的个人设备上本地运行。
3. 潜在的应用场景与厂商的兴趣点
尽管没有官宣合作,但可以预见,智能硬件厂商正密切关注BitNet,原因在于:
▪ 打造真正的端侧AI:智能硬件厂商们(如苹果、谷歌、三星)一直致力于将更多AI功能本地化,以提升响应速度、保护用户隐私并降低对云服务的依赖。BitNet的轻量化和高效性使其成为实现这一目标的理想技术。
▪ 降低成本和功耗:在竞争激烈的消费电子市场,任何能够降低硬件成本和延长电池续航的技术都极具吸引力。BitNet无需高端GPU,并能显著降低能耗,这完美契合了厂商的需求。
▪ 催生新的智能体验:通过在设备上本地运行强大的语言模型,可以实现更智能、更无缝的交互体验,例如更自然的语音助手、离线的实时翻译、设备端的文档摘要和内容创作等。
目前,BitNet与消费电子硬件的适配尚处于“黎明前夜”。虽然我们还没有看到支持BitNet架构的手机或笔记本电脑上市,但所有的基础工作都在迅速推进。开发者社区和研究人员正在利用bitnet.cpp等工具,在现有的Arm和x86硬件上不断进行测试和优化,验证其可行性和巨大优势。
可以预见,随着技术的成熟和相关工具链的完善,未来一到两年内,我们很有可能会看到一些领先的硬件厂商宣布与微软合作,或推出专为运行此类1-bit模型而优化的芯片或硬件解决方案。
04.
国内厂商基于BitNet架构的
“端侧AI”模型轻量化尝试
虽然目前还没有知名的国内终端厂商官宣支持BitNet,但所有头部厂商都认识到,将AI能力从云端下放到手机、PC、汽车等边缘和终端电子设备上,是提升用户体验、保护数据隐私和构建技术护城河的关键。
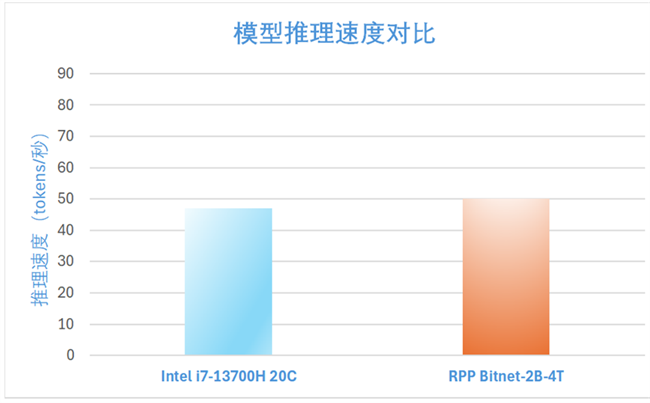
据笔者了解,边缘AI芯片厂商芯动力是目前国内唯一在尝试适配BitNet模型的企业。芯动力已经成功实现业界首家微软BitNet大语言模型的本地化高效适配,其自主研发的RPP架构完美支持BitNet-b1.58-2B-4T模型推理。

在适配过程中,芯动力技术团队采用了微软官方推荐的I2_S编码方式,确保模型性能的充分发挥。值得一提的是,该方案在联想ThinkPad 16p Gen6这款革命性AI PC上展现出卓越的推理能力——作为全球首款搭载dNPU专用AI加速芯片的笔记本电脑,其内置的RPP dNPU加速卡为大型语言模型的高效运行提供了硬件级保障。
性能测试数据表明,芯动力RPP的推理效率已超越微软官方公布的基准表现,这标志着国产AI加速技术在边缘计算领域取得重大突破,为下一代智能终端的AI应用普及奠定了坚实基础。
可以预见,随着BitNet及其背后的1-bit LLM技术被证明其价值,国内厂商很可能会迅速吸收这些先进理念,并将其融入到自家的技术体系中,甚至与芯片合作伙伴共同推出专门针对此类超低比特模型进行优化的硬件,从而在这场全球性的AI效率革命中占据有利位置。
05.
BitNet模型与新兴具身机器人应用
BitNet模型与具身机器人的结合,代表了低功耗AI与物理智能体融合的前沿方向,下面从技术协同、应用场景、产业生态及未来挑战四个维度来简要分析一下其发展前景:
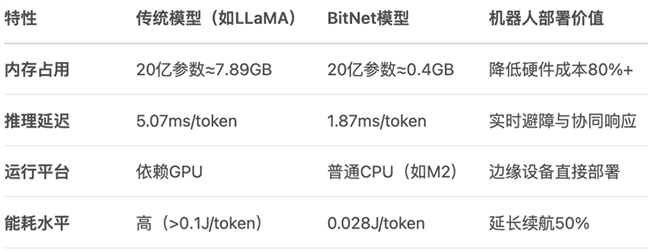
技术协同:低精度计算与机器人硬件的深度适配。BitNet的核心优势在于超低内存资源消耗、处理器(CPU+NPU)友好性及实时响应能力,可满足具身机器人对本地化部署、计算处理能力与能耗的最优化、物理空间的量化理解,以及动态环境的毫秒级决策等要求。
应用场景:从工业到消费领域的规模化渗透。BitNet支持轻量级端到端控制,可灵活适配AGV、装配机械臂等工业自动化设备。在消费与服务领域,BitNet可协助小型化设备(如扫地机器人、陪护机器人)实现复杂指令理解与环境交互,解决传统终端算力瓶颈问题。
产业生态:硬件-软件协同创新。bitnet.cpp框架可为BitNet提供底层加速,未来可以拓展至ROS等机器人操作系统。基于Arm或RISC-V的异构计算架构(CPU+NPU)芯片,像芯动力的RPP,可以适配BitNet量化计算,极大提升能效比。
未来挑战:BitNet依赖微软专用框架(bitnet.cpp),尚未兼容PyTorch生态,制约开发者生态扩展。其1.58位量化方法在训练时可能比较复杂,耗时较长,会削弱复杂场景推理能力(如多物体动态交互),需与RoboBrain 2.0等空间模型融合补偿。此外,现有机器人关节模组(如滚柱丝杠、力矩电机)能耗仍高,需与AI能效提升同步优化。
未来突破路径包括模型轻量化--扩展BitNet至多模态输入(视觉+力控);开源生态--推动BitNet接入ROS 2.0或鸿蒙系统,吸引开发者社区;算力-执行器协同:结合谐波减速器、力矩传感器等硬件创新,打造高能效机器人关节。
06.
BitNet有望引爆家电、汽车和手机市场
当强大的AI能力可以被低成本、高效率地嵌入到每一个硬件设备中时,它不但可以降低计算成本,提升智能设备能效比,甚至将彻底颠覆现有产业的形态和价值链。
1. 手机产业:从“智能手机”到“AI手机”的终极跃迁
▪ 现状:目前的手机AI多是“伪端侧”,许多功能仍需联网调用云端API。
▪ BitNet带来的未来:
超级个人助理:手机可以本地运行一个真正懂你的、拥有长期记忆的AI助理,它了解你的所有习惯和信息(因为数据不出本地),能主动为你规划日程、管理信息、提供建议。
永不掉线的实时功能:无论在飞机上还是地下室,实时翻译、文档摘要、图像处理等功能都能瞬时完成。
极致个性化:AI可以根据你的使用习惯,实时、动态地优化手机的性能、功耗和用户界面,成为独一无二的“个性化手机”。
2. 汽车产业:加速迈向真正的“智能座舱”与“自动驾驶”
▪ 现状:智能汽车对网络和云端算力高度依赖,自动驾驶的决策延迟和安全性是巨大挑战。
▪ BitNet带来的未来:
瞬时决策的自动驾驶:复杂的环境感知和驾驶决策模型可以在车内本地完成,摆脱网络延迟,极大地提升自动驾驶的安全性与可靠性。
会思考的智能座舱:车载语音助手不再是机械的“命令执行者”,而是能理解复杂语境、结合车辆状态和外部环境进行多轮自然对话的“智能副驾”。
隐私保护:车辆的行驶轨迹、车内对话等敏感数据都无需上传云端,最大程度保护用户隐私。
3. 家电产业:从“功能性产品”到“有智慧的家庭成员”
▪ 现状:智能家居依然停留在“手机App控制”或简单的语音指令阶段,设备间联动生硬,并不“智能”。
▪ BitNet带来的未来:
主动服务的家电:你的空调会根据你的睡眠状态、室外天气和你的体感习惯,主动调节到最舒适的温度;你的冰箱能根据现有食材,主动为你生成菜谱并联动烤箱设置程序。
无处不在的自然交互:你不再需要寻找手机或智能音箱,可以直接对任何家电用自然语言下达指令,甚至通过一个眼神、一个手势与之交互。
真正的智能家庭中枢:所有家电拥有了本地的“大脑”,它们可以协同工作,形成一个统一的、无需云端协调的智能网络,真正实现“全屋智能”。
07.
结语
微软提出的BitNet框架为边缘AI的加速普及带来了新的活力,也为中国企业提供了一个在AI应用领域“换道超车”的绝佳机会。智能硬件成为AI的最佳载体,而中国强大的设计制造和软硬件整合能力,将成为AI发展的核心优势。
类似BitNet的模型将会如雨后春笋一样出现,而这对于硬件的灵活性要求极高,像芯动力的RPP架构不但兼容CUDA生态,而且可快速适配和部署新的模型,及时获取生态开发者反馈并快速迭代,从而加速AI在边缘和端侧的普及。
参考资料:
1. ithome.com.tw,微軟發表首個超過20億參數的1-bit模型同樣效能但更省電、不占記憶體 - iThome
2. arxiv.org,BitNet b1.58 2B4T Technical Report - arXiv
3. arxiv.org,[2310.11453] BitNet: Scaling 1-bit Transformers for Large Language Models - arXiv
4. medium.com,Reimagining AI Efficiency: A Practical Guide to Using BitNet's 1-Bit LLM on CPUs Without Sacrificing Performance | by Kondwani Nyirenda | Medium
5. arxiv.org,BitNet: Scaling 1-bit Transformers for Large Language Models - arXiv
6. reddit.com,BitNet - Inference framework for 1-bit LLMs : r/LocalLLaMA – Reddit
7. pub.towardsai.net,Understanding 1.58-bit Large Language Models | Arun Nanda - Towards AI
8. medium.com,BitNet b1.58 2B4T: The Dawn of Ternary Intelligence | by Arman Kamran | Medium
9. pdf.dfcfw.com,端侧智能行业: 人工智能重要应用,产品落地爆发在即
10. opensource.siemens.com,端侧通用人工智能大模型发展趋势及技术解析















-
 招商蛇口旗下伊敦新春开门红丨满房映初心 温情暖人间
招商蛇口旗下伊敦新春开门红丨满房映初心 温情暖人间 -
 四大热卖热水器同场竞技,德国宝即热式综合优势显著
四大热卖热水器同场竞技,德国宝即热式综合优势显著 -
 九章云极DataCanvas免费提供100度算力包,极速部署不蒸馏满血版DeepSeek-R1!
九章云极DataCanvas免费提供100度算力包,极速部署不蒸馏满血版DeepSeek-R1! -
 AlphaGPT 与DeepSeek强强联合,打造更好用的法律AI产品
AlphaGPT 与DeepSeek强强联合,打造更好用的法律AI产品 -
 鲸心涤携手IPTV强势登陆蛇年春晚
鲸心涤携手IPTV强势登陆蛇年春晚 -
 韶音发布OpenFit 2 开放式耳机,开启舒适听音新时代
韶音发布OpenFit 2 开放式耳机,开启舒适听音新时代 -
 安德医美大健康产业园正式动工:引领创新力,打造全球一流医美科研园区
安德医美大健康产业园正式动工:引领创新力,打造全球一流医美科研园区 -
 万店掌携手DeepSeek大模型:重塑连锁门店智能巡店新标杆
万店掌携手DeepSeek大模型:重塑连锁门店智能巡店新标杆 -
 壹树健康于第十四届公益节荣获“医疗健康企业责任典范奖”及创始人宋怡然获评“年度责任商业领袖”
壹树健康于第十四届公益节荣获“医疗健康企业责任典范奖”及创始人宋怡然获评“年度责任商业领袖” -
 舒华体育助力2025年哈尔滨第九届亚冬会
舒华体育助力2025年哈尔滨第九届亚冬会